We’ve built a few digital texts this semester that can serve as web pages but what do we do with them now that we have them? To share things with the world, we need to host them on the Internet, so that we can share them quickly and easily with others. Thankfully, this is an easy task!
This chapter will discuss:
- How does the Internet work?
- How do servers work?
- How can I host things online?
The Internet
The Internet, the tool you’re using to read this chapter, is a network of networks originally designed to share scientific information between institutions. This animated GIF shows the expansion of the Internet from 1969 to 1989. The original connections are between SRI (The Stanford Research Institute); University of California, Santa Barbara; University of California, Los Angeles; and University of Utah. It was also partly created as part of a defense department initiative to build a set of tools to share information across a network that had been partly destroyed by nuclear war.
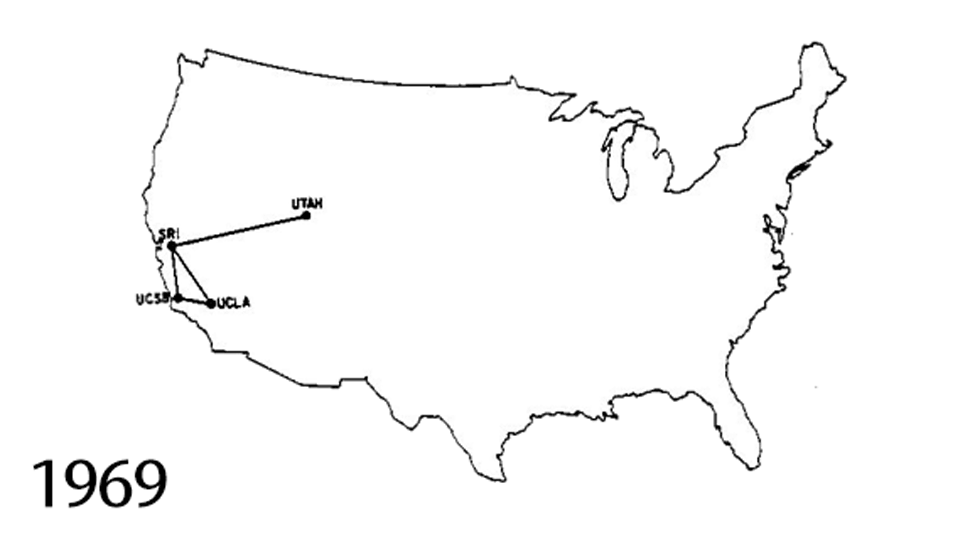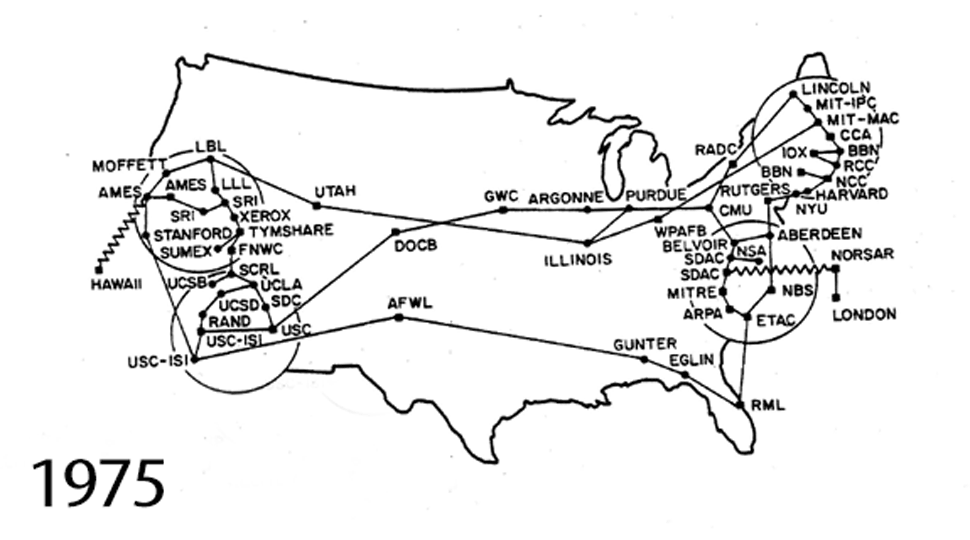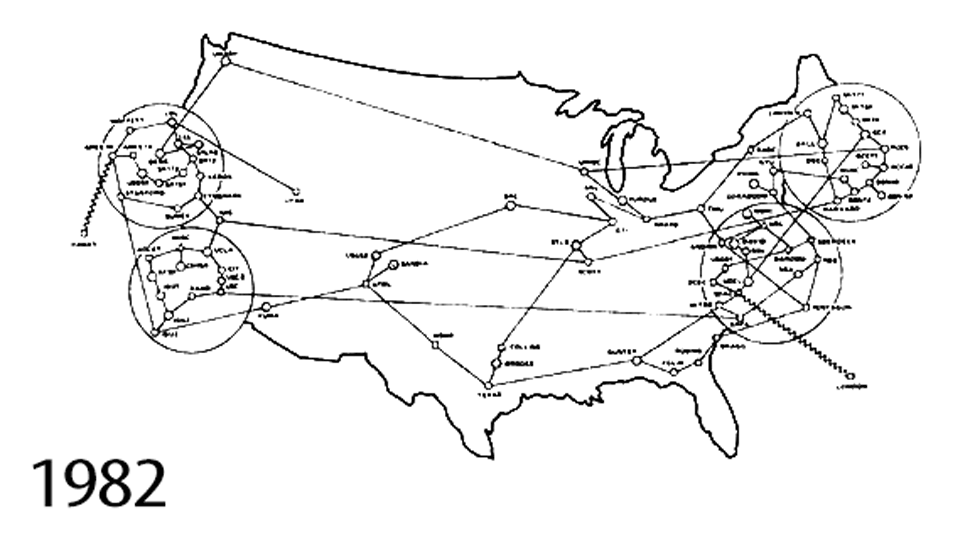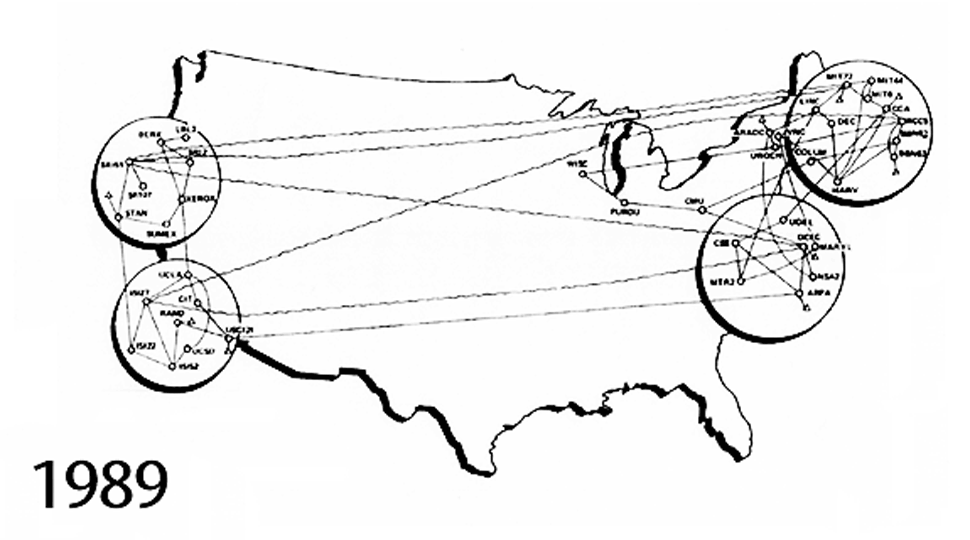{kind=link}
But what does calling it “a network of networks” actually mean? A network is a way of connecting any kind of points in mathematics, which is used as a metaphor for how computers link together to share information. Networks allow computers to share data amongst themselves and between their users, whether local or remote.
If you have a wifi router in your house connected to a modem, your house has a network in it. Your home network connects through a modem to your Internet Service Provider’s network (an ISP is usually the cable or phone company). You pay the ISP to connect their network to the Internet. Similarly, your cellphone connects to a different network composed of cellular towers that spreads across the world. You are, once again, paying for the service of having that cell network connected to the broader Internet. If you access your university’s wireless network, you are connected to their network, which is in turn connected to the Internet.
The Internet, then, is a bridge that exists between these and many other privately operated networks. It’s the glue that makes it possible for you to read your university email on your cellphone or when you are at home.
How does the Internet do it?
Every device connected to the Internet as an address that is unique to it (just like how a mailing address uniquely identifies an IRL building). Internet addresses consist of four numbers between 0 and 256, so an address might be 127.0.0.1 or 192.168.1.15. These are referred to as “IP addresses” because they are assigned as part of the Internet Protocol, which is the set of messages that govern how the Internet works. If something has an IP address, it is considered addressable on the Internet.
Side Note: 127.0.0.1 and 192.168.1.15, which I used as examples above, are special local IP addresses. Every device on the Internet assigns 127.0.0.1 to itself, so that you can always talk to yourself on the Internet (this will matter more when we start running our own web server in a few sections). Additionally, IP addresses that start with 192.168 are “private” according to the Internet. Your computer at home likely has one of these addresses assigned to it, because you only actually pay for a single Internet connection from your ISP and your wifi router shares that between multiple devices on your home’s private network.
So, with everything addressable on the Internet, the task is to find a site we want to visit. Back when the Internet was very small, most sites just used their IP address, as the whole thing was tiny. However, very quickly, humans (being humans) needed a bit more memorable information than just four arbitrary numbers.
This is where domain names come in. A domain name is the Internet addresses we are most familiar with, things like www.google.com or www.tamu.edu. Behind the scenes on the Internet, there is a network of computers that are called Domain Name System servers (or DNS servers) whose job is to translate domain names into IP addresses so that we can browse the Internet. These DNS servers use a dictionary data structure to translate from IP addresses to domain names and from domain names to IP addresses.
Your computer is assigned a DNS server when it connects to the Internet. Most likely, this server is operated by your ISP, though you could use Google or Quad9’s servers which offer nominally better service (or you could be like me and run your own DNS server at good old 127.0.0.1 on every computer in your house). DNS servers talk to one another to determine the best mapping between a domain name and an IP, but there are 13 root-level servers that authorize everything.
So, when you browse to www.google.com, your computer first queries its DNS server to get an IP address. There are command line utilities that let us look at these DNS queries, so I ran one (dig google.com) and it produced the following:
; <<>> DiG 9.16.21 <<>> google.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 32834
;; flags: qr rd ra; QUERY: 1, ANSWER: 6, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION:
;google.com. IN A
;; ANSWER SECTION:
google.com. 3600 IN A 64.233.185.102
google.com. 3600 IN A 64.233.185.100
google.com. 3600 IN A 64.233.185.113
google.com. 3600 IN A 64.233.185.139
google.com. 3600 IN A 64.233.185.138
google.com. 3600 IN A 64.233.185.101
;; Query time: 203 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Wed Oct 20 08:22:40 CDT 2021
;; MSG SIZE rcvd: 135
The portion labelled ANSWER SECTION is the most important. It shows us the IP addresses associated with google.com. If we were to open one of these in our web browser, we would be connected to Google’s site. Click the previous link if you don’t believe me!
Note: As I mentioned, every computer that exists assigns itself the address of 127.0.0.1. This special IP is also assigned the domain name localhost, so you can always connect to your local computer using localhost or 127.0.0.1.
Now that we’ve found Google, our browser can connect and start showing us some search results.
Or can it?
How do servers work?
We have written some HTML. We have just learned how the Internet helps us find remote computers. But how does someone like Google show us the HTML we see when we visit their page?
The answer is “servers.”
Servers are computers that provide content when accessed by clients. Your computer is a client. Your phone is a client. Where your email comes from is a sever. Where this webpage comes from is a server.
However, this identity is not fixed. If a computer has an IP address on the public Internet (such as your cable modem or your cellphone), it can be treated as a server. Client/server is a relationship that can change. When my computer has content to give it is a server; when it wants to access other content, it is a client.
Network architects and software developers find it easier to dedicate computers to the role of server, which is why you hear things about email servers or web servers (usually when things fail). Besides, you wouldn’t to serve Google off your personal computer.
Server Software
Computers working as servers need to be running special software that can translate client requests into appropriate data. These client requests are defined by protocols. A protocol is a pre-arranged set of messages agreed upon by a client and a server. The kind of paroles used by spies to identify one another are an analog of these protocols, which often involve lots of additional messages to verify what version of a protocol is being spoken and specifically what data is needed.
Every computer that connects to the Internet, in addition to having a unique address, also has 65536 (which is 216) individual ports open. If an IP address is like an IRL building’s address, think of ports as like windows or doors, each a separate way into the building. Each port can be attached to a particular piece of software, which is said to “listen” on its assigned port. While any port could be used, protocols define particular ports for particular services. 80 is HTTP; 443 is HTTPS; 21 is FTP; 22 is SSH; and so on. So, whenever your browser connects to a webpage, it connects to port 80 on the particular computer that lives at the address we got from the DNS server above (DNS uses port 53, btw).
When it connects to a server, your web browser is speaking to a special piece of called a “daemon” that interprets a particular protocol, in this case HTTP. Back in the day, I could connect directly to these daemons without using a browser and transmit HTTP commands directly to them. This is increasingly difficult because most of the Internet is switching to the significantly more secure HTTPS (the “S” stands for “Secure”) protocol. However, I can run a version of this chapter on my local computer to show you what an HTTP transaction looks like.
I’m using a command line program called telnet to connect to port 80 on my computer, where my copy of this document is running. At my command line, I type telnet 127.0.0.1 80 and hit Enter. The server sends me the following welcome message:
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
And waits for my command. I send it an HTTP request by typing GET /courses/engl460/08-server.html HTTP/1.1 and pressing Enter twice (HTTP requests can have multiple pieces of data attached, each set off by a newline). The command consists of three parts:
- The action (
GET). There are two main HTTP commands (GETandPOST) which map to accessing HTML documents and sending form data back to the server. - The file name (
/courses/engl460/08-server.html). This is the file I wish to access on the remote server.- Remember when we talked about file paths? This should look familiar.
- The protocol version (
HTTP/1.1). This is me telling the server what language I’m speaking to it in.
The server responds with:
HTTP/1.1 200 OK
Etag: 774ed4-2362-6170555f
Content-Type: text/html; charset=utf-8
Content-Length: 9058
Last-Modified: Wed, 20 Oct 2021 17:43:59 GMT
Cache-Control: private, max-age=0, proxy-revalidate, no-store, no-cache, must-revalidate
Server: WEBrick/1.6.0 (Ruby/2.7.2/2020-10-01)
Date: Thu, 21 Oct 2021 15:15:57 GMT
Connection: Keep-Alive
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Begin Jekyll SEO tag v2.6.1 -->
<title>ENGL 460: What is a Server? | ENGL 460: What is a Server?</title>
<meta name="generator" content="Jekyll v3.9.0" />
<meta property="og:title" content="ENGL 460: What is a Server?" />
<meta property="og:locale" content="en_US" />
<link rel="canonical" href="http://localhost:4000/courses/engl460/08-server.html" />
<meta property="og:url" content="http://localhost:4000/courses/engl460/08-server.html" />
<meta property="og:site_name" content="ENGL 460: What is a Server?" />
<script type="application/ld+json">
{"url":"http://localhost:4000/courses/engl460/08-server.html","@type":"WebPage","headline":"ENGL 460: What is a Server?","@context":"https://schema.org"}</script>
<!-- End Jekyll SEO tag -->
<link rel="stylesheet" href="/courses/assets/css/style.css?v=7affc81249d5b7e2ee19b2f1de1077398dbe286e">
</head>
<body>
<article class="container-lg px-3 my-5 markdown-body">
<div class="columns">
<div class="column col-12">
<h1><a href="http://localhost:4000/courses/">ENGL 460: What is a Server?</a></h1>
</div>
[...]
</html>
Connection closed by foreign host.
I excerpted the full document (because it’s long), but it sends me, on the first line (HTTP/1.1 200 OK) a response code (200 is “everything is fine”; if you’ve seen a 404 error, that’s the HTTP response code for “file not found”), followed by some information about the document (in the form of a simple dictionary), including the type of the content (Content-type) and how many bytes long the document is (Content-length). Then it skips two lines and sends me the document.
If I were a web browser instead of a person typing into telnet, I would render that HTML into the webpage you are currently reading.
Putting it All Together: The URL
When we go to Google, we usually type google.com into our browser’s address bar and press Enter. Our browser actually does some translating on this, too, because at this point browser makers know we, as users, are pretty lazy. Back in the early days of the Internet, typing google.com into an early version of Netscape might not actually get you where you want to go. google.com is a DNS name, but it is not enough to find information on the Internet.
For that, we need something called a Universal Resource Locator (or URL).
A URL combines everything we have been talk about into one convenient package that can be fed into the Internet to find information. Let’s look at a URL for Google:
http://www.google.com:80/
That doesn’t look too different from what we’ve already seen, but we’ve added a few things, which are all elements of a URL:
http://– Before the domain name of the server, set off by://is the URL’s protocol. In this case, we are using HTTP as we are accessing a website.- If we were accessing an FTP server, we could do so in our browser by setting the protocol to
ftp:// - If we were using HTTPS, we could set the protocol to
https://
- If we were accessing an FTP server, we could do so in our browser by setting the protocol to
www.google.com– This identifies the specific computer to which we want to connect. It has several elements:wwwis the name of a computer running at Google (it’s probably several thousand computers acting as one)google.com– Identifies the network.- This works for any website. My website,
andrew.pilsch.com, is a computer (andrew) which is a member of thepilsch.comdomain. - The TAMU English department page is
www.english.tamu.edu, which is thewwwcomputer running on theenglish.tamu.edusubdomain, which is itself a part of the largertamu.edudomain. You can have an infinite level of specificity in these computer names wwwas the name of a webserver is a convention but not part of the HTTP specification. Some domains (likewww.english.tamu.eduunless they’ve fixed it) won’t work without thewww, but, mostly, this is widespread enough that you can leave off thewwwand your computer will assume the computer you want.
:80– This specifies the port to which we want to connect.- The default HTTP port is 80, so we don’t have to include it.
- If we were connecting to a different port, we would need to provide it, however, as our browsers default to port 80.
/– This is the name of the resource we want on the computer we want to access via the port and protocol we specified./is the root node of any filesystem, so, by convention, it is the main page for a particular site.- For this page, the file is named
/courses/engl460/08-server.html, which corresponds to a file on the computer namedoncomouse.github.io.
Linking in HTML Using URLS
This section is very important and will likely break your webpage at some point.
The domain name (google.com) is all that your browser requires. However, in HTML, any resource (such as an image source or an href on an anchor tag) not on the same computer as our site has to include the protocol in front of the domain name. HTML is less forgiving than our browser’s address bar.
We talked about . and .. in the chapter on files. We can use these as short hand for resources on our current computer. For instance, if I wanted to link to the files chapter, I could type ./04-file.html. My browser can translate the dot (.) to the current URL (https://oncomouse.github.io/courses/engl460/08-server.html) with the name of the file (08-server.html) removed, so https://oncomouse.github.io/courses/engl460. Then it would tack on /04-file.thml to get https://oncomouse.github.io/courses/engl460/04-file.html, which is the link I want.
If I wanted to link to the main page of my course repository from this file, I could type ../. My browser can translate the dot (.) to the current URL (https://oncomouse.github.io/courses/engl460/08-server.html) with the name of the file (/08-server.html) and the current directory (/engl460) removed. Then it would tack on / to get https://oncomouse.github.io/courses/.
If 04-file.html were on a different server, I would have to type the full URL starting with the protocol (https:// in this case).
Getting Yourself Online
In order to host your own webpage on the Internet, you would need a web host to agree to provide you with a URL and a place to store files. Free site builders such as Wiix do this for you while hiding a lot of the background stuff we talked about in this chapter.
If you wanted to start building your site yourself, you would need to purchase server space and register your own domain name (sites like GoDaddy can do that for you). Then you could start posting HTML in your portion of the Internet and have your own personal website.
If, however, you wanted something in the middle between everything done for you and doing everything yourself, a program like Jekyll can help. Jekyll is a piece of software called a static site generator that can translate little bits of Markdown and HTML into a fully functional website for you. For instance, this site is written using Jekyll. You can view the source of my course repository on Github, where I host it.
Jekyll lets me write these chapters in Markdown and lets you see them in HTML automatically.
Additionally, GitHub, a free site used by many software projects to manage distributed work on coding, offers free Jekyll sites to any repository hosted there. It gives us the ability to use what we have already been learning (Markdown, JSON, HTML, Tracery, Twine) to make websites. And all for free!